ANYmal demonstrates how hybrid mobility can benefit quadrupedal robots.

ANYmal demonstrates how hybrid mobility can benefit quadrupedal robots.

There is no doubt that the future of transport is autonomous. Tesla is already rolling out a beta version of full self driving and that will be released fully in 2021, I am sure. From robotaxis to freight transport, our lives will get easier, cheaper and more convenient and for those with current mobility issues, the change will be even greater. Here I look at some of the ways that all our lives, the environment and the places we live will change…for the better. I cannot wait…can you?
In The Mind Blowing Future Of Transportation — How Self Driving Cars Will Change The World, I will look at the future of autonomous vehicles and how they will change our world…for the better.
Autonomous cars are the future, and whether it is geo-constrained services like Waymo or Tesla full self driving which could well be fully rolled out in 2021, self driving cars are the future of transportation, and many other vehicle sectors, such as long haul transportation.
They will make the roads safer and they will give us back massive amounts of previously wasted time, to do with as we desire.
Are you looking forward to our autonomous future?
Let me know in the comments.
And here is another topic you might find interesting about future technologies just around the corner.

Previous research has shown that eye contact, in human-human interaction, elicits increased affective and attention related psychophysiological responses. In the present study, we investigated whether eye contact with a humanoid robot would elicit these responses. Participants were facing a humanoid robot (NAO) or a human partner, both physically present and looking at or away from the participant. The results showed that both in human-robot and human-human condition, eye contact versus averted gaze elicited greater skin conductance responses indexing autonomic arousal, greater facial zygomatic muscle responses (and smaller corrugator responses) associated with positive affect, and greater heart deceleration responses indexing attention allocation. With regard to the skin conductance and zygomatic responses, the human model’s gaze direction had a greater effect on the responses as compared to the robot’s gaze direction. In conclusion, eye contact elicits automatic affective and attentional reactions both when shared with a humanoid robot and with another human.
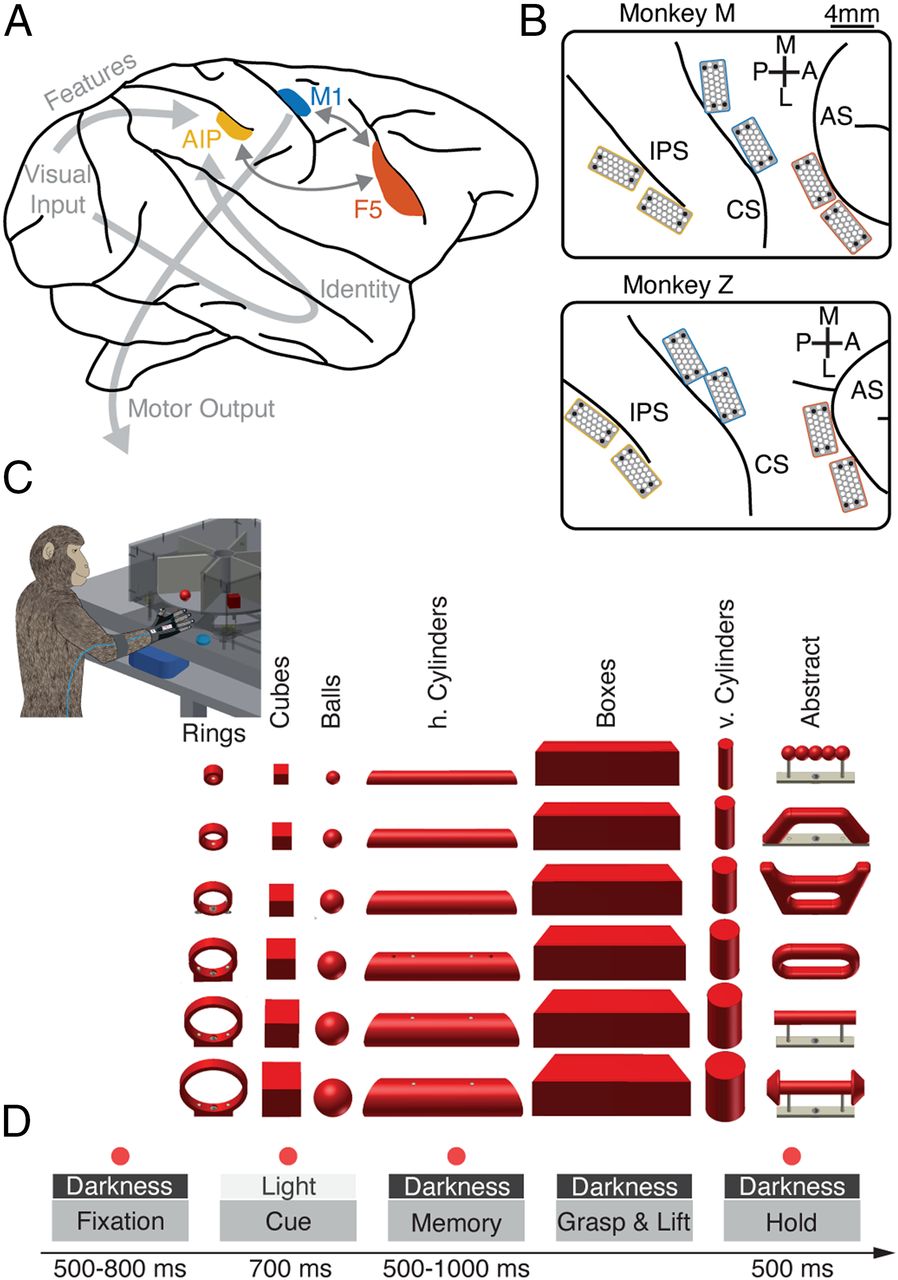
Grasping objects is something primates do effortlessly, but how does our brain coordinate such a complex task? Multiple brain areas across the parietal and frontal cortices of macaque monkeys are essential for shaping the hand during grasping, but we lack a comprehensive model of grasping from vision to action. In this work, we show that multiarea neural networks trained to reproduce the arm and hand control required for grasping using the visual features of objects also reproduced neural dynamics in grasping regions and the relationships between areas, outperforming alternative models. Simulated lesion experiments revealed unique deficits paralleling lesions to specific areas in the grasping circuit, providing a model of how these areas work together to drive behavior.
One of the primary ways we interact with the world is using our hands. In macaques, the circuit spanning the anterior intraparietal area, the hand area of the ventral premotor cortex, and the primary motor cortex is necessary for transforming visual information into grasping movements. However, no comprehensive model exists that links all steps of processing from vision to action. We hypothesized that a recurrent neural network mimicking the modular structure of the anatomical circuit and trained to use visual features of objects to generate the required muscle dynamics used by primates to grasp objects would give insight into the computations of the grasping circuit. Internal activity of modular networks trained with these constraints strongly resembled neural activity recorded from the grasping circuit during grasping and paralleled the similarities between brain regions.

The study of visual illusions has proven to be a very useful approach in vision science. In this work we start by showing that, while convolutional neural networks (CNNs) trained for low-level visual tasks in natural images may be deceived by brightness and color illusions, some network illusions can be inconsistent with the perception of humans. Next, we analyze where these similarities and differences may come from. On one hand, the proposed linear eigenanalysis explains the overall similarities: in simple CNNs trained for tasks like denoising or deblurring, the linear version of the network has center-surround receptive fields, and global transfer functions are very similar to the human achromatic and chromatic contrast sensitivity functions in human-like opponent color spaces. These similarities are consistent with the long-standing hypothesis that considers low-level visual illusions as a by-product of the optimization to natural environments. Specifically, here human-like features emerge from error minimization. On the other hand, the observed differences must be due to the behavior of the human visual system not explained by the linear approximation. However, our study also shows that more ‘flexible’ network architectures, with more layers and a higher degree of nonlinearity, may actually have a worse capability of reproducing visual illusions. This implies, in line with other works in the vision science literature, a word of caution on using CNNs to study human vision: on top of the intrinsic limitations of the L + NL formulation of artificial networks to model vision, the nonlinear behavior of flexible architectures may easily be markedly different from that of the visual system.

Raspberry Pi and ROS Robotics are versatile exciting tools that allow you to build many wondrous projects. However, they are not always the easiest systems to manage and use… until now.
The Ultimate Raspberry Pi & ROS Robotics Developer Super Bundle will turn you into a Raspberry Pi and ROS Robotics expert in no time. With over 39 hours of training and over 15 courses, the bundle leaves no stone unturned.
There is almost nothing you won’t be able to do with your new-found bundle on Raspberry Pi and ROS Robotics.
Northwestern researchers have developed a first-of-its-kind soft, aquatic robot that is powered by light and rotating magnetic fields. These life-like robotic materials could someday be used as “smart” microscopic systems for production of fuels and drugs, environmental cleanup or transformative medical procedures.

Voicebots, humanoids and other tools capture memories for future generations.
What happens after we die—digitally, that is? In this documentary, WSJ’s Joanna Stern explores how technology can tell our stories for generations to come.
Old photos, letters and tapes. Tech has long allowed us to preserve memories of people long after they have died. But with new tools there are now interactive solutions, including memorialized online accounts, voice bots and even humanoid robots. WSJ’s Joanna Stern journeys across the world to test some of those for a young woman who is living on borrowed time. Photo illustration: Adele Morgan/The Wall Street Journal.
More from the Wall Street Journal:
Visit WSJ.com: http://www.wsj.com.
Visit the WSJ Video Center: https://wsj.com/video.
On Facebook: https://www.facebook.com/pg/wsj/videos/
On Twitter: https://twitter.com/WSJ
On Snapchat: https://on.wsj.com/2ratjSM
#WSJ #Tech #Documentary

Is it possible to read a person’s mind by analyzing the electric signals from the brain? The answer may be much more complex than most people think.
Purdue University researchers—working at the intersection of artificial intelligence and neuroscience—say a prominent dataset used to try to answer this question is confounded, and therefore many eye-popping findings that were based on this dataset and received high-profile recognition are false after all.
The Purdue team performed extensive tests over more than one year on the dataset, which looked at the brain activity of individuals taking part in a study where they looked at a series of images. Each individual wore a cap with dozens of electrodes while they viewed the images.
