Reinforcement learning algorithms are only now starting to be applied in business settings — but could help companies solve complicated problems. Here’s how.
Most machine learning systems leverage historical data to make predictions. But learning through trial and error lead to more creative solutions.
As content moderation continues to be a critical aspect of how social media platforms work — one that they may be pressured to get right, or at least do better in tackling — a startup that has built a set of data and image models to help with that, along with any other tasks that require automatically detecting objects or text, is announcing a big round of funding.
Hive, which has built a training data trove based on crowdsourced contributions from some 2 million people globally, which then powers a set of APIs that can be used to identify automatically images of objects, words and phrases — a process used not just in content moderation platforms, but also in building algorithms for autonomous systems, back-office data processing, and more — has raised $85 million in a Series D round of funding that the startup has confirmed values it at $2 billion.
“At the heart of what we’re doing is building AI models that can help automate work that used to be manual,” said Kevin Guo, Hive’s co-founder and CEO. “We’ve heard about RPA and other workflow automation, and that is important too but what that has also established is that there are certain things that humans should not have to do that is very structural, but those systems can’t actually address a lot of other work that is unstructured.” Hive’s models help bring structure to that other work, and Guo claims they provide “near human level accuracy.”
AI systems can lead to race or gender discrimination.
The US Federal Trade Commission has warned companies against using biased artificial intelligence, saying they may break consumer protection laws. A new blog post notes that AI tools can reflect “troubling” racial and gender biases. If those tools are applied in areas like housing or employment, falsely advertised as unbiased, or trained on data that is gathered deceptively, the agency says it could intervene.
“In a rush to embrace new technology, be careful not to overpromise what your algorithm can deliver,” writes FTC attorney Elisa Jillson — particularly when promising decisions that don’t reflect racial or gender bias. “The result may be deception, discrimination — and an FTC law enforcement action.”
As Protocol points out, FTC chair Rebecca Slaughter recently called algorithm-based bias “an economic justice issue.” Slaughter and Jillson both mention that companies could be prosecuted under the Equal Credit Opportunity Act or the Fair Credit Reporting Act for biased and unfair AI-powered decisions, and unfair and deceptive practices could also fall under Section 5 of the FTC Act.
Understanding the genetics of complex diseases, especially those related to the genetic differences among ethnic groups, is essentially a big data problem. And researchers need more data.
1000, 000 genomes
To address the need for more data, the National Institutes of Health has started a program called All of Us. The project aims to collect genetic information, medical records and health habits from surveys and wearables of more than a million people in the U.S. over the course of 10 years. It also has a goal of gathering more data from underrepresented minority groups to facilitate the study of health disparities. The All of Us project opened to public enrollment in 2018, and more than 270000 people have contributed samples since. The project is continuing to recruit participants from all 50 states. Participating in this effort are many academic laboratories and private companies.
Developing Next Generation Artificial Intelligence To Serve Humanity — Dr. Patrick Bangert, Vice President of AI, Samsung SDS.
Dr. Patrick D. Bangert, is Vice President of AI, and heads the AI Engineering and AI Sciences teams, at Samsung SDS is a subsidiary of the Samsung Group, which provides information technology (IT) services, and are active in research and development of emerging IT technologies such as artificial intelligence (AI), blockchain, Internet of things (IoT) and Engineering Outsourcing.
Dr. Bangert is responsible for the Brightics AI Accelerator, a distributed ML training and automated ML product, and for X.insights, a data center intelligence platform.
Among his other responsibilities, Dr. Bangert acts as a visionary for the future of AI at Samsung.
Before joining Samsung, Dr. Bangert spent 15 years as CEO at Algorithmica Technologies, a machine learning software company serving the chemicals and oil and gas industries. Prior to that, he was assistant professor of applied mathematics at Jacobs University in Germany, as well as a researcher at Los Alamos National Laboratory and NASA’s Jet Propulsion Laboratory.
Dr. Bangert obtained his machine learning PhD in mathematics and his Masters in theoretical physics from University College London.
A German native, Dr. Bangert grew up in Malaysia and the Philippines, and later lived in the UK, Austria, Nepal and USA. He has done business in many countries and believes that AI must serve humanity beyond mere automation of routine tasks.
Dr. Bangert is also an accomplished author, having written two books including — Machine Learning and Data Science in the Oil and Gas Industry: Best Practices, Tools, and Case Studies and Optimization for Industrial Problems.
Whatever business a company may be in, software plays an increasingly vital role, from managing inventory to interfacing with customers. Software developers, as a result, are in greater demand than ever, and that’s driving the push to automate some of the easier tasks that take up their time.
Productivity tools like Eclipse and Visual Studio suggest snippets of code that developers can easily drop into their work as they write. These automated features are powered by sophisticated language models that have learned to read and write computer code after absorbing thousands of examples. But like other deep learning models trained on big datasets without explicit instructions, language models designed for code-processing have baked-in vulnerabilities.
“Unless you’re really careful, a hacker can subtly manipulate inputs to these models to make them predict anything,” says Shashank Srikant, a graduate student in MIT’s Department of Electrical Engineering and Computer Science. “We’re trying to study and prevent that.”
Yesterday Nvidia officially dipped a toe into quantum computing with the launch of cuQuantum SDK, a development platform for simulating quantum circuits on GPU-accelerated systems. As Nvidia CEO Jensen Huang emphasized in his keynote, Nvidia doesn’t plan to build quantum computers, but thinks GPU-accelerated platforms are the best systems for quantum circuit and algorithm development and testing.
As a proof point, Nvidia reported it collaborated with Caltech to develop “a state-of-the-art quantum circuit simulator with cuQuantum running on NVIDIA A100 Tensor Core GPUs. It generated a sample from a full-circuit simulation of the Google Sycamore circuit in 9.3 minutes on Selene, a task that 18 months ago experts thought would take days using millions of CPU cores.”
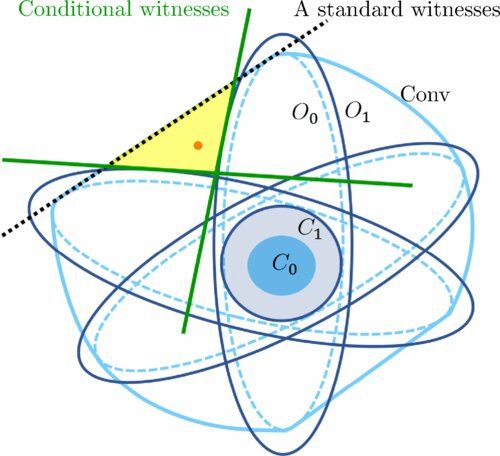
Physicists from Swansea University are part of an international research collaboration which has identified a new technique for testing the quality of quantum correlations.
Quantum computers run their algorithms on large quantum systems of many parts, called qubits, by creating quantum correlations across all of them. It is important to verify that the actual computation procedures lead to quantum correlations of desired quality.
However, carrying out these checks is resource-intensive as the number of tests required grows exponentially with the number of qubits involved.