Researchers from ETH Zurich collaborated with Nvidia develop a novel method for teaching robots how to walk before they ever take a step in real life.

Researchers from ETH Zurich collaborated with Nvidia develop a novel method for teaching robots how to walk before they ever take a step in real life.

Deepfake videos are well-known; many examples of what only appear to be celebrities can be seen regularly on YouTube. But while such videos have grown lifelike and convincing, one area where they fail is in reproducing a person’s voice. In this new effort, the team at UoC found evidence that the technology has advanced. They tested two of the most well-known voice copying algorithms against both human and voice recognition devices and found that the algorithms have improved to the point that they are now able to fool both.
The two algorithms— SV2TTS and AutoVC —were tested by obtaining samples of voice recordings from publicly available databases. Both systems were trained using 90 five-minute voice snippets of people talking. They also enlisted the assistance of 14 volunteers who provided voice samples and access to their voice recognition devices. The researchers then tested the two systems using the open-source software Resemblyzer—it listens and compares voice recordings and then gives a rating based on the similar two samples are. They also tested the algorithms by using them to attempt to access services on voice recognition devices.
The researchers found the algorithms were able to fool the Resemblyzer nearly half of the time. They also found that they were able to fool Azure (Microsoft’s cloud computing service) approximately 30 percent of the time. And they were able to fool Amazon’s Alexa voice recognition system approximately 62% of the time.

The University of Bristol is part of an international consortium of 13 universities in partnership with Facebook AI, that collaborated to advance egocentric perception. As a result of this initiative, we have built the world’s largest egocentric dataset using off-the-shelf, head-mounted cameras.
Progress in the fields of artificial intelligence (AI) and augmented reality (AR) requires learning from the same data humans process to perceive the world. Our eyes allow us to explore places, understand people, manipulate objects and enjoy activities—from the mundane act of opening a door to the exciting interaction of a game of football with friends.
Egocentric 4D Live Perception (Ego4D) is a massive-scale dataset that compiles 3,025 hours of footage from the wearable cameras of 855 participants in nine countries: UK, India, Japan, Singapore, KSA, Colombia, Rwanda, Italy, and the US. The data captures a wide range of activities from the ‘egocentric’ perspective—that is from the viewpoint of the person carrying out the activity. The University of Bristol is the only UK representative in this diverse and international effort, collecting 270 hours from 82 participants who captured footage of their chosen activities of daily living—such as practicing a musical instrument, gardening, grooming their pet, or assembling furniture.
“In the not-too-distant future you could be wearing smart AR glasses that guide you through a recipe or how to fix your bike—they could even remind you where you left your keys,” said Principal Investigator at the University of Bristol and Professor of Computer Vision, Dima Damen.


Today we learned that an art group is planning a spectacle to draw attention to a provocative use of our industrial robot, Spot. To be clear, we condemn the portrayal of our technology in any way that promotes violence, harm, or intimidation. It’s precisely the sort of thing the company tries to get out in front of. After decades of killer-robot science-fiction, it doesn’t take much to make people jump any time an advanced robot enters the picture. It’s the automaton version of Rule 34 (in staunch defiance of Asimov’s First Law of Robotics): If a robot exists, someone has tried to weaponize it.
Full Story:
Let’s talk about strapping guns to the backs of robots. I’m not a fan (how’s that for taking a stand?). When MSCHF did it with Spot back in February, it was a thought experiment, art exhibit and a statement about where society might be headed with autonomous robotics. And most importantly, of course, it was a paintball gun. Boston Dynamics clearly wasn’t thrilled with the message it was sending, noting:

The math is pretty basic. How many satellites are going to go up over the next decade? How many solar panels will they need? And how many are being manufactured that fit the bill? Turns out the answers are: a lot, a hell of a lot, and not nearly enough. That’s where Regher Solar aims to make its mark, by bringing the cost of space-quality solar panels down by 90% while making an order of magnitude more of them. It’s not exactly a modest goal, but fortunately the science and market seem to be in favor, giving the company something of a tailwind. The question is finding the right balance between cost and performance while remaining relatively easy to manufacture. Of course, if there was an easy answer there, someone would already be doing that.
Full Story:
Intech Company is the ultimate source of the latest AI news. It checks trusted websites and collects bests pieces of AI information.

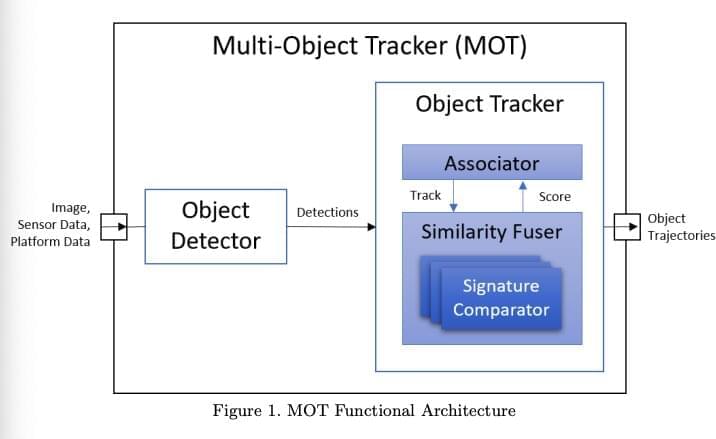
To efficiently navigate their surrounding environments and complete missions, unmanned aerial systems (UASs) should be able to detect multiple objects in their surroundings and track their movements over time. So far, however, enabling multi-object tracking in unmanned aerial vehicles has proved to be fairly challenging.
To efficiently navigate their surrounding environments and complete missions, unmanned aerial systems (UASs) should be able to detect multiple objects in their surroundings and track their movements over time. So far, however, enabling multi-object tracking in unmanned aerial vehicles has proved to be fairly challenging.
Researchers at Lockheed Martin AI Center have recently developed a new deep learning technique that could allow UASs to track multiple objects in their surroundings. Their technique, presented in a paper pre-published on arXiv, could aid the development of better performing and more responsive autonomous flying systems.
“We present a robust object tracking architecture aimed to accommodate for the noise in real-time situations,” the researchers wrote in their paper. “We propose a kinematic prediction model, called deep extended Kalman filter (DeepEKF), in which a sequence-to-sequence architecture is used to predict entity trajectories in latent space.”

Founders tend to think responsible AI practices are challenging to implement and may slow the progress of their business. They often jump to mature examples like Salesforce’s Office of Ethical and Humane Use and think that the only way to avoid creating a harmful product is building a big team. The truth is much simpler.
I set out to learn how founders were thinking about responsible AI practices on the ground by speaking with a handful of successful early-stage founders and found many of them were implementing responsible AI practices.
Only they didn’t call it that. They just call it “good business.”

{kind=link}