When tuned up, old algorithms can match the abilities of their successors.


A machine-learning algorithm has been developed by scientists in Japan to breathe new life into old molecules. Called BoundLess Objective-free eXploration, or Blox, it allows researchers to search chemical databases for molecules with the right properties to see them repurposed. The team demonstrated the power of their technique by finding molecules that could work in solar cells from a database designed for drug discovery.
Chemical repurposing involves taking a molecule or material and finding an entirely new use for it. Suitable molecules for chemical repurposing tend to stand apart from the larger group when considering one property against another. These materials are said to be out-of-trend and can display previously undiscovered yet exceptional characteristics.
‘In public databases there are a lot of molecules, but each molecule’s properties are mostly unknown. These molecules have been synthesised for a particular purpose, for example drug development, so unrelated properties were not measured,’ explains Koji Tsuda of the Riken Centre for Advanced Intelligence and who led the development of Blox. ‘There are a lot of hidden treasures in databases.’


Tissue biopsy slides stained using hematoxylin and eosin (H&E) dyes are a cornerstone of histopathology, especially for pathologists needing to diagnose and determine the stage of cancers. A research team led by MIT scientists at the Media Lab, in collaboration with clinicians at Stanford University School of Medicine and Harvard Medical School, now shows that digital scans of these biopsy slides can be stained computationally, using deep learning algorithms trained on data from physically dyed slides.
Pathologists who examined the computationally stained H&E slide images in a blind study could not tell them apart from traditionally stained slides while using them to accurately identify and grade prostate cancers. What’s more, the slides could also be computationally “de-stained” in a way that resets them to an original state for use in future studies, the researchers conclude in their May 20 study published in JAMA Network Open.
This process of computational digital staining and de-staining preserves small amounts of tissue biopsied from cancer patients and allows researchers and clinicians to analyze slides for multiple kinds of diagnostic and prognostic tests, without needing to extract additional tissue sections.


Zhou Yi was terrible at math. He risked never getting into college. Then a company called Squirrel AI came to his middle school in Hangzhou, China, promising personalized tutoring. He had tried tutoring services before, but this one was different: instead of a human teacher, an AI algorithm would curate his lessons. The 13-year-old decided to give it a try. By the end of the semester, his test scores had risen from 50% to 62.5%. Two years later, he scored an 85% on his final middle school exam.
“I used to think math was terrifying,” he says. “But through tutoring, I realized it really isn’t that hard. It helped me take the first step down a different path.”
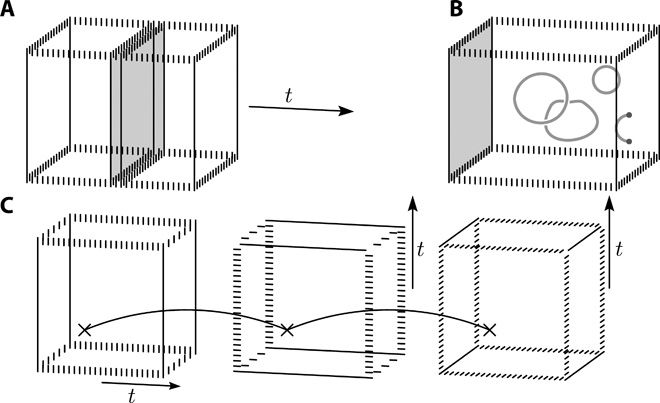
Fault-tolerant logic gates will consume a large proportion of the resources of a two-dimensional quantum computing architecture. Here we show how to perform a fault-tolerant non-Clifford gate with the surface code; a quantum error-correcting code now under intensive development. This alleviates the need for distillation or higher-dimensional components to complete a universal gate set. The operation uses both local transversal gates and code deformations over a time that scales with the size of the qubit array. An important component of the gate is a just-in-time decoder. These decoding algorithms allow us to draw upon the advantages of three-dimensional models using only a two-dimensional array of live qubits. Our gate is completed using parity checks of weight no greater than four. We therefore expect it to be amenable with near-future technology. As the gate circumvents the need for magic-state distillation, it may reduce the resource overhead of surface-code quantum computation considerably.
A scalable quantum computer is expected to solve difficult problems that are intractable with classical technology. Scaling such a machine to a useful size will necessarily require fault-tolerant components that protect quantum information as the data is processed (1–4). If we are to see the realization of a quantum computer, its design must respect the constraints of the quantum architecture that can be prepared in the laboratory. In many cases, for instance, superconducting qubits (5–7), this restricts us to two-dimensional architectures.
Leading candidate models for fault-tolerant quantum computation are based on the surface code (3, 8) due to its high threshold (9) and multitude of ways of performing Clifford gates (10). Universal quantum computation is possible if this gate set is supplemented by a non-Clifford gate. Among the most feasible approaches to realize a non-Clifford gate is by the use of magic-state distillation (11). However, this is somewhat prohibitive as a large fraction of the resources of a quantum computer will be expended by these protocols (12, 13).

High-quality data is the fuel that powers AI algorithms. Without a continual flow of labeled data, bottlenecks can occur and the algorithm will slowly get worse and add risk to the system.
It’s why labeled data is so critical for companies like Zoox, Cruise and Waymo, which use it to train machine learning models to develop and deploy autonomous vehicles. That need is what led to the creation of Scale AI, a startup that uses software and people to process and label image, lidar and map data for companies building machine learning algorithms. Companies working on autonomous vehicle technology make up a large swath of Scale’s customer base, although its platform is also used by Airbnb, Pinterest and OpenAI, among others.
The COVID-19 pandemic has slowed, or even halted, that flow of data as AV companies suspended testing on public roads — the means of collecting billions of images. Scale is hoping to turn the tap back on, and for free.

Any time you log on to Twitter and look at a popular post, you’re likely to find bot accounts liking or commenting on it. Clicking through and you can see they’ve tweeted many times, often in a short time span. Sometimes their posts are selling junk or spreading digital viruses. Other accounts, especially the bots that post garbled vitriol in response to particular news articles or official statements, are entirely political.
It’s easy to assume this entire phenomenon is powered by advanced computer science. Indeed, I’ve talked to many people who think machine learning algorithms driven by machine learning or artificial intelligence are giving political bots the ability to learn from their surroundings and interact with people in a sophisticated way.
During events in which researchers now believe political bots and disinformation played a key role—the Brexit referendum, the Trump-Clinton contest in 2016, the Crimea crisis—there is a widespread belief that smart AI tools allowed computers to pose as humans and help manipulate the public conversation.