Over the past few years, classical convolutional neural networks (cCNNs) have led to remarkable advances in computer vision. Many of these algorithms can now categorize objects in good quality images with high accuracy.
However, in real-world applications, such as autonomous driving or robotics, imaging data rarely includes pictures taken under ideal lighting conditions. Often, the images that CNNs would need to process feature occluded objects, motion distortion, or low signal to noise ratios (SNRs), either as a result of poor image quality or low light levels.
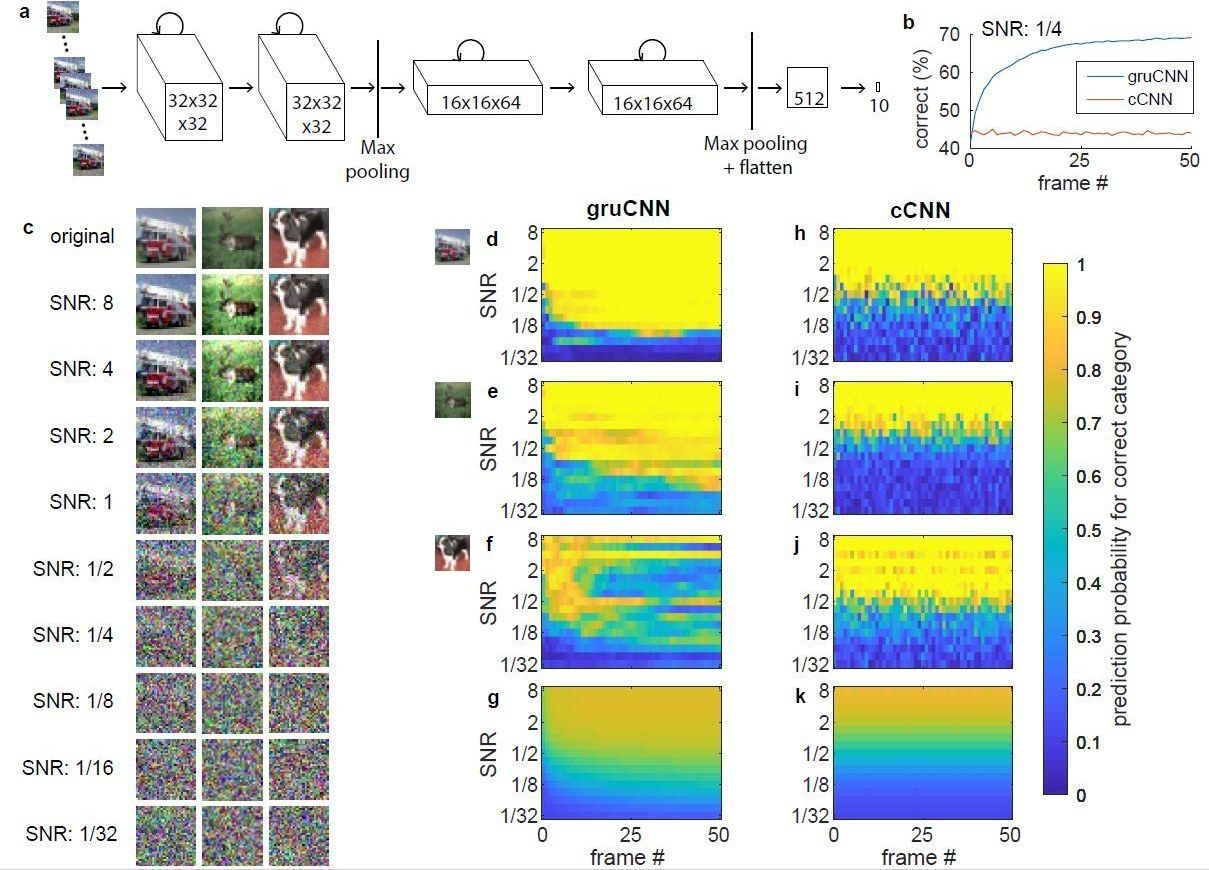
Although cCNNs have also been successfully used to de-noise images and enhance their quality, these networks cannot combine information from multiple frames or video sequences and are hence easily outperformed by humans on low quality images. Till S. Hartmann, a neuroscience researcher at Harvard Medical School, has recently carried out a study that addresses these limitations, introducing a new CNN approach for analyzing noisy images.