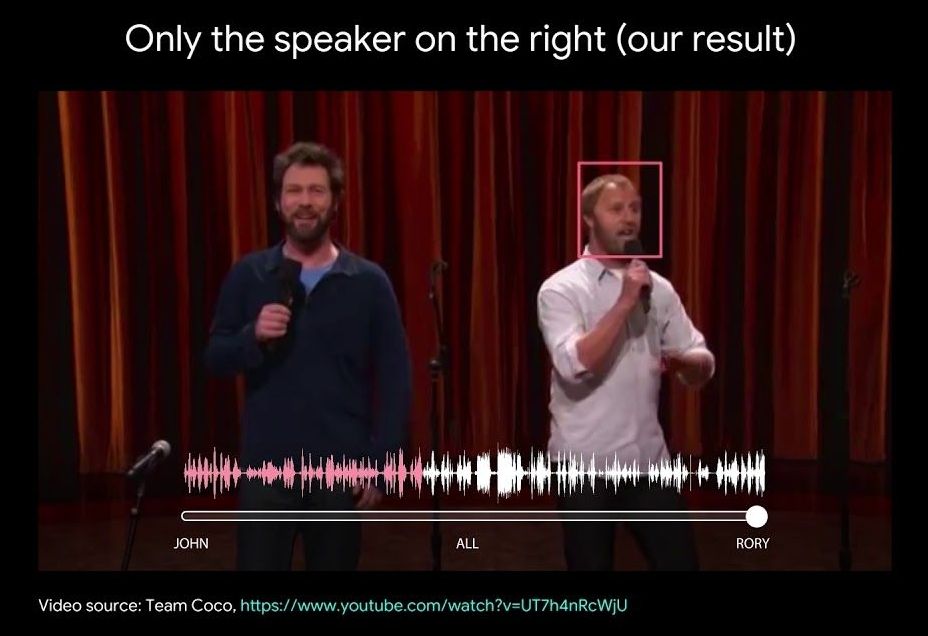
People are remarkably good at focusing their attention on a particular person in a noisy environment, mentally “muting” all other voices and sounds. Known as the cocktail party effect, this capability comes natural to us humans. However, automatic speech separation — separating an audio signal into its individual speech sources — while a well-studied problem, remains a significant challenge for computers.
In “Looking to Listen at the Cocktail Party”, we present a deep learning audio-visual model for isolating a single speech signal from a mixture of sounds such as other voices and background noise. In this work, we are able to computationally produce videos in which speech of specific people is enhanced while all other sounds are suppressed. Our method works on ordinary videos with a single audio track, and all that is required from the user is to select the face of the person in the video they want to hear, or to have such a person be selected algorithmically based on context. We believe this capability can have a wide range of applications, from speech enhancement and recognition in videos, through video conferencing, to improved hearing aids, especially in situations where there are multiple people speaking.